密度推定を用いた回帰
今回は,特に実用性はないけど,回帰をより深く理解するためにはいいかもしれない,密度推定(Density Estimation)を用いた回帰というのを紹介したいと思う. まず,回帰は「条件付き確率の期待値」を求めるという枠組みだ. フォーマルに書くと,入力を,出力をとすると,以下の関数を求めるのが回帰である.
ここで,「右の積分はどうやって計算するんだ?」という疑問が生まれる. の形によっては,上の関数を解析的に求めることが可能だが,そうではない場合ももちろんある. こういう場合は,例えば,期待値をサンプリングにより近似する,重点サンプリング(importance Sampling)という手法で計算できる. 重点サンプリングでは,代理分布を用いて,上記の積分を以下のようにサンプル近似する.
ただし,である. つまり,代理分布にサンプリング可能な(乱数を生成できる)確率密度関数を持って来ればいいというわけだ. ここで,重みを以下のように定義する.
上の式からわかるように,とが推定できれば,上の重みは計算できる. というわけで今回はこれをカーネル密度推定(Kernel Density Estimation, KDE)で推定してみる.
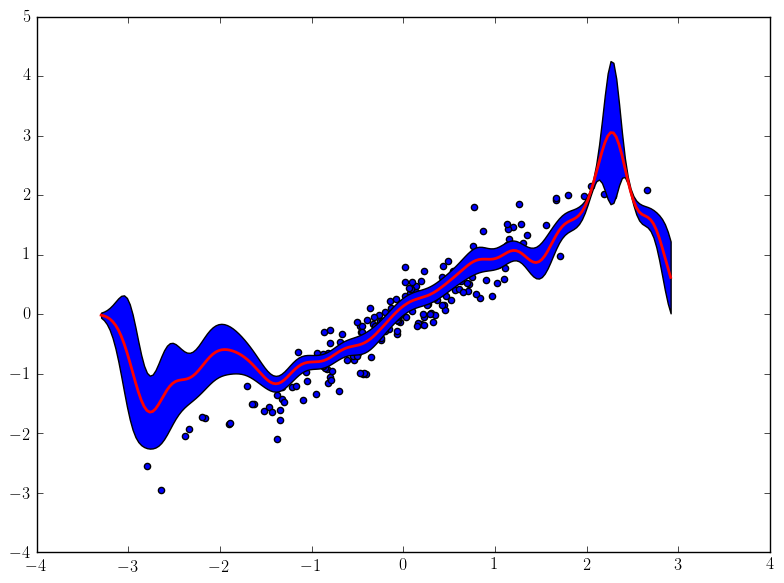
では,実験してみる.結果は以下のようになった.青い点がサンプルで,赤い線が推定した関数である. ちなみに,この手法だと分散も計算できるので,それも合わせてプロットしてみた. みればわかるように,サンプルが少なくて推定結果が曖昧なところでは分散が高くなっている.なお,コードは記事の最後に添付する.
今回は密度推定を用いた回帰というのを紹介してみた. これを使えば,実は,Baysian Optimizationぽいことができるので,次はそれについて書きたいと思う.