ラプラス正則化 (Laplacian Regularization) を使った半教師付き分類
教師ありデータと教師なしデータを 用いて学習する枠組みを半教師付き学習と呼ぶ. 少量の教師ありデータと大量の教師なしデータを持っているという設定は非常に現実的で, 半教師付き学習は実用的な枠組みだと思う.
ラプラス正則化の基本的なアイデアは,「似ているものは同じラベルを持つ」というもの. 具体的には,類似度行列を受け取り, 類似度が高いものは予測値も近くなるような正則化を行う. 今回はラプラス正則化のリッジ回帰への適用例を考えてみる. ラプラス正則化を施したリッジ回帰の最適化問題は以下で与えられる.
最後の項がラプラス正則化項. この項は結局ラプラス行列というもので表されるのでラプラス正則化と呼ばれている.
ここでは,非線形な決定境界を表現するために,には以下で定義するRBFカーネルモデルを用いることにする.
$$ f_{\theta}(x) = \sum_{\ell=1}^n \theta_\ell k(x,x_\ell), \ k(x,x_\ell)=\exp\left(-\gamma\|x-x_\ell\|^2\right) $$
コードは以下のようになった.
https://gist.github.com/nkt1546789/add3f33ceee65294d0a8
実行結果はこんな感じ. 左が訓練データで赤と青がラベル付きデータで白い点がラベルなしデータ. このように,たった2つの教師ありデータから正しく分類ができている.
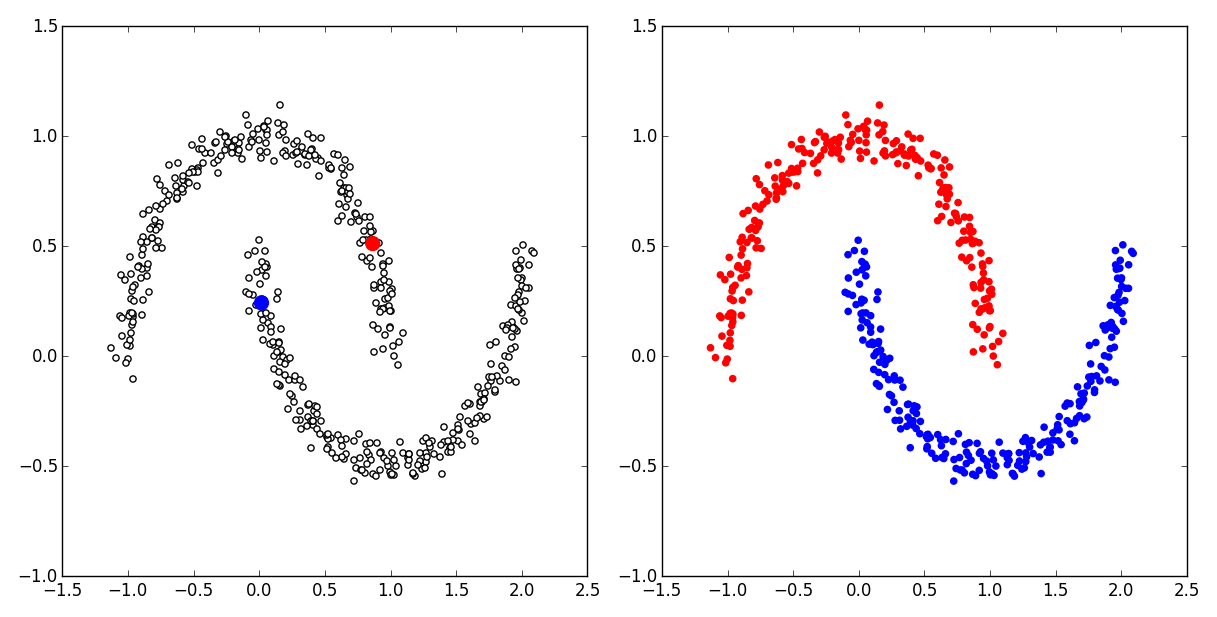
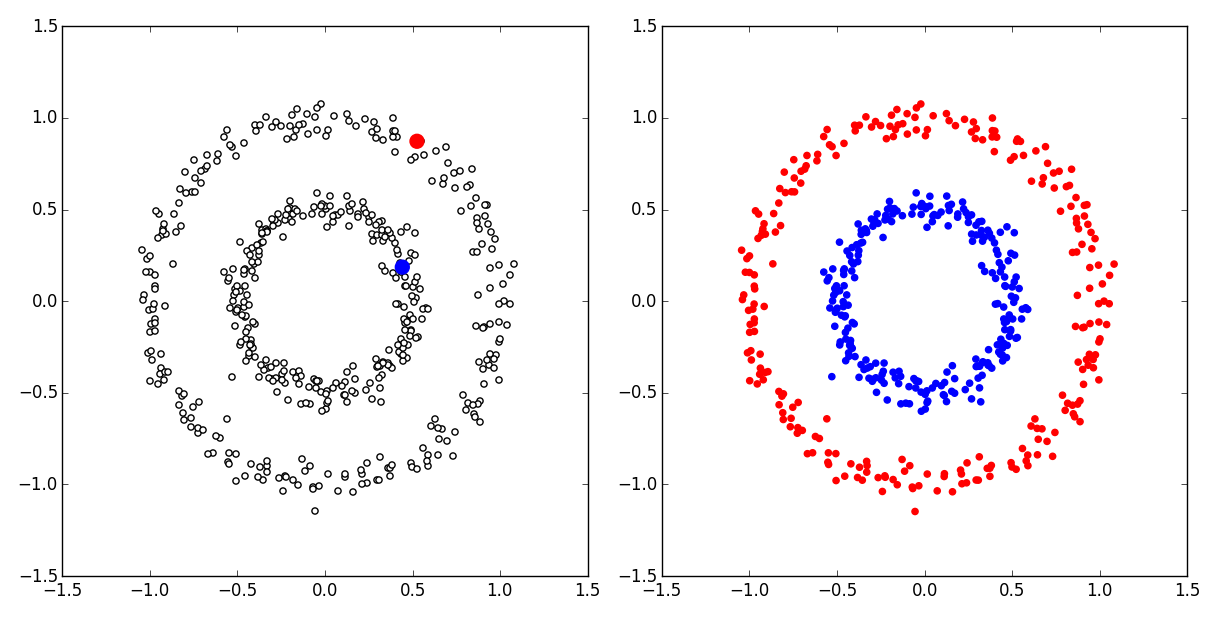
ちなみに,RBFカーネルモデルにすべてのデータ点を使っているものポイント.
ラプラス正則化は目的関数に一つ項を加えるだけで, 教師なしデータも活用できるのでお手軽で性能も素晴らしいので是非使ってみてください. もちろん,上の例のように,十分な量の訓練データが与えられていない場合,パラメータチューニングが非常に難しいです. 教師ありデータが十分にあれば,交差検定ができる.