Gaussianに従う確率変数のエントロピーの推定
連続型確率変数のエントロピーの計算法を調べてもなかなか良いのが出てこなかったので苦労した。 というわけで、それに関連するポスト。確率変数のエントロピーは次式で定義される。
今回の実験では、求めるエントロピーの真の値がわかっている必要があるので1変数正規分布を利用する。 1変数正規分布に従う連続型確率変数のエントロピーは次式で求められる。
今回は標準正規分布を用いる。 なおこの設定では当たり前だが、確率密度関数は既知だとする。 確率密度関数が既知なので、それに従う乱数をn個生成し、その確率密度を計算すると、n個の確率密度によるサンプルを作ることができる。 つまりエントロピーを以下のようにサンプル近似する。
実行結果は以下のようになった。
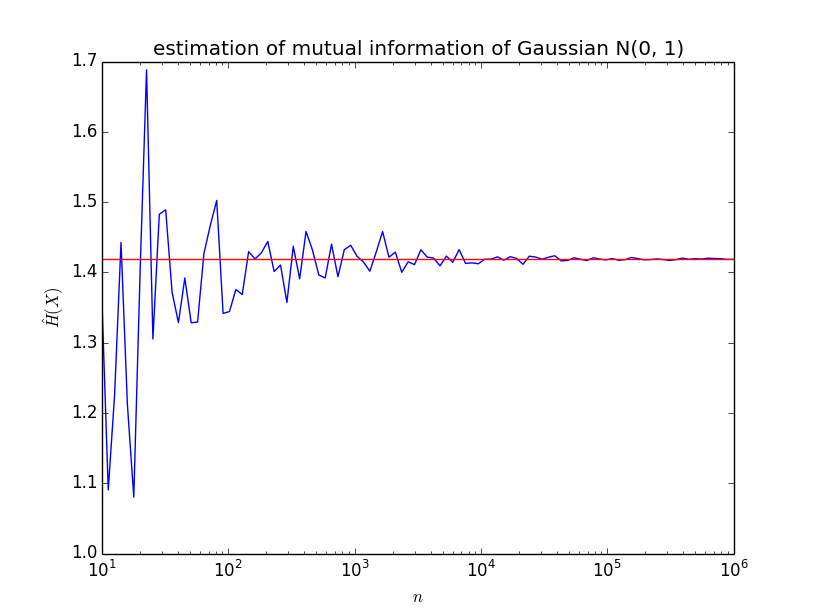
ここから、サンプル数を増やしていけば、真の値に近づいていく、つまり、
が言える。 結論として、エントロピーはサンプル近似することができるということがわかった。 ただし、ここで疑問がある。 通常は、サンプルのみが与えられていて、確率密度関数は未知である。 そこで、確率密度関数を推定して、が得られたとする。 次は確率密度のサンプルを生成したいわけだが、これは可能なのだろうか。 すなわち任意の関数に従う乱数を生成することは可能なのだろうか。 これが疑問で仕方ないので、また調べる。 なお、使ったコードは以下である。
# coding: utf-8
import numpy as np
import pylab as pl
from scipy import stats
th = np.log(np.sqrt(2*np.pi*np.e))
print "theoritical:", th
ns = np.logspace(1, 6, 100)
hs = [np.sum(-np.log(stats.norm.pdf(stats.norm.rvs(0, 1, n))))/n for n in ns]
ths = np.repeat(th, 100)
pl.semilogx(ns, hs)
pl.semilogx(ns, ths, c="r")
pl.title("estimation of entropy of Gaussian N(0, 1)")
pl.xlabel("$$n$$")
pl.ylabel(r"$$\hat{H}(X)$$")
pl.show()