ソフトマージンSVMのヒンジ損失最小化学習としての解釈とその実装
前回,ハードマージンSVMの定式化について書いたので, 今回はソフトマージンSVMの定式化をしようと思います. さらに,それをヒンジ損失最小化学習として解釈できることを示し, 最後に確率的勾配法を使って実装したいと思います.
さて,ハードマージンSVMの最適化問題は以下で与えられます.
しかし,与えられたデータに対して,この制約を満たす超平面が存在しない場合,実行可能領域が空集合となり,この最適化問題が解を持たなくなってしまいます. そこで,制約を緩和するために,全てのサンプルに対してを導入し,最適化問題を以下のように書き換えます.
これは,訓練データでの誤識別をある程度許容することに相当します. 我々のゴールは汎化能力の獲得,つまり,未知のデータに対する誤識別率を最小化することなので,訓練データを全て正しく識別する必要はありません. さらに,訓練データに完全にフィットさせることは,汎化能力の低下を引き起こす原因にもなります.そのような意味でも,制約の緩和は有用です.
この最適化問題では,の時,の誤識別を許容します. さらに,は小さい方が望ましいので,目的関数に加えて同時に最小化します. は識別率をコントロールするハイパーパラメータです.
さて,ここで,を以下のように定義すると,
上の最適化問題は,以下のように書き換えられます.
ここで,を損失関数とみると,経験リスク最小化学習になっていることがわかります.損失関数はヒンジ損失と呼ばれています.
ここから実装について,書きたいと思います.
オンライン機械学習 (機械学習プロフェッショナルシリーズ)を参考にしています.
SVMは二次計画法で解くこともできますが,今回は確率的勾配法(正確にはIncremental Gradient Method)を使って解きたいと思います.
として,簡単のために とします.すると,切片がに吸収され,上の最適化問題は,
と書けます. 確率的勾配法では,適当にサンプルを一つ取り出して,それに対応する目的関数,
の勾配を求めます.その勾配を用いて,パラメータをと更新します.これを収束まで繰り返します.
しかし,ヒンジ損失はを満たす点で微分不可能なため,劣勾配を考えます.
これを踏まえると,アルゴリズムは以下のようになります.
- ランダムにを取り出す.
- 以下のようにを更新 (はステップサイズ)
実装してみました.
結果は以下のようになりました.
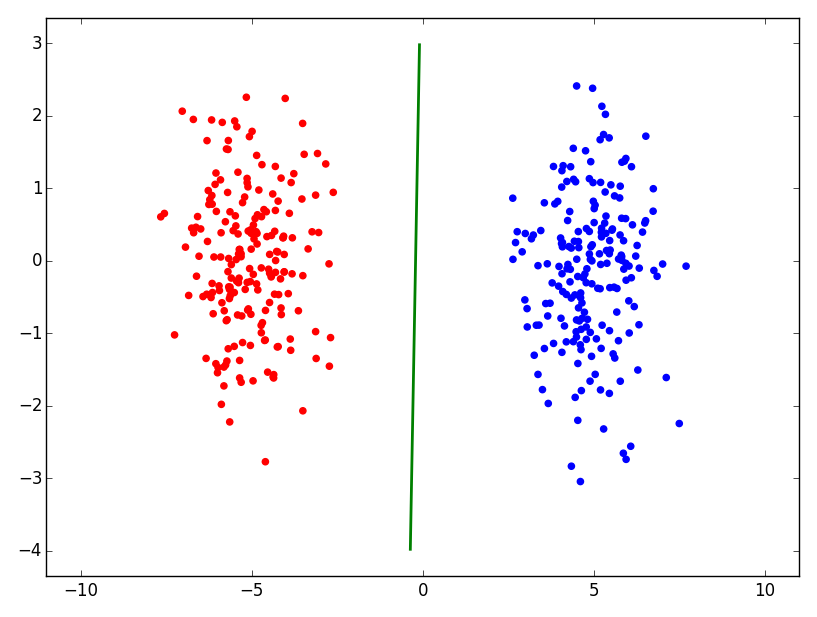
なお,以下に書いたように,実装においてはステップサイズの決定が非常に難しいです.
実際に使用する時は,scikit-learnのsklearn.linear_model.SGDClassifierを使うのが賢明でしょう.
今回はソフトマージンSVMを定式化し,確率的勾配法を用いて実装してみた. とりあえず簡単な人工データでうまく動くことを確認した. この実装は実用に耐えうるものではないので,簡単なデモだと思ってください^^. 読んでいただき,ありがとうございました.